
How to reduce quantisation noise in 8-bit samples
If you google for something like "how to remove noise in 8-bit audio", you will typically get a lot of results explaining that you need to apply "dithering" in order to get rid of something called "quantisation noise".
Aha... and what exactly is dithering and quantisation noise then?
Well, quantisation noise (sometimes also called quantisation distortion) is the noise that is created when reducing the bit-resolution from 16-bit (65536 distinctive sample values) to 8-bit (256 distinctive sample values). One technique for converting 16-bit to 8-bit is simply to truncate the 16-bit sample, which basically means to just take the 8-bit byte part of the 16-bit sample. This means that a 16-bit value between 0 and 255 will be converted to the 8-bit value of 0. And the 16-bit value between 256 and 511 will be converted to the 8-bit value of 1, and so forth.
In other words, each 8-bit value will lose precision with up to 255 values compared to the 16-bit signal - and that's what's called quantisation - because every 255 values gets reduced to a single value. And it is this lost data that causes the noise. The noise is actually the sound of the missing data.
Ok, so what is dithering then, and how is that supposed to solve this? Well, dithering is simply the process of "adding random noise" to the signal in order to hide or disguise the quantisation distortion, and give back the audio a more natural sound. It supposedly replaces the quantisation noise with a "white hissing" noise - which apparently many people prefer instead.
And there are many different kinds of dithering. The most common one is called Triangular Probability Density Function (TPDF), and you can apply such dithering to your sound with the following SoX command:
sox 16bitinput.wav -b 8 8bitoutput.s8 dither -S
Ok then, so far so good. Sounds interesting. But when we search for these things online, we tend to forget a simple but important reality: It's not 1995 anymore, and all of these articles about dithering are written by people who most likely doesn't even know what an Amiga is. They use socalled "modern professional" equipment, and often aren't even talking about 16-bit to 8-bit, but rather 24-bit to 16-bit or even 32-bit to 24-bit. And the samplerates they use are usually 96 kHz or more - not 16 kHz as we use on Amiga.
Therefore, the dithering techniques they describe does not give the same results when targeting 8-bit 16 kHz, like we do on (stock) Amiga. Mainly because of the low samplerate we use.
The human ear can hear frequencies between 20 hz and 20 kHz, and is most sensitive to frequencies from 2 kHz to 5 kHz. Some people can even hear as low as 12 Hz and as high as 28 kHz. (And it is of course typically in this group you will find the audiophile people).
When you apply dithering to a 96 kHz signal - i.e. random small values on each sample value - it effectively becomes a frequency of its own that varies between 24 kHz and 48 kHz - meaning well outside the human hearing range. That's why it works. That's how you effectively move the noise away from the human hearing range.
Not so on Amiga though, because here we typically use samplerates between 8 kHz and 27 kHz. If we apply dithering to a 16 kHz sample, we're effectively adding a noise frequency that varies between 4 kHz and 8 kHz - which is no where near outside the human hearing range. It actually happens to be in the frequency range we are most sensitive to. In other words: It's the exact opposite result of what we're looking for. We're not getting rid of the quantisation noise, but rather just adding an extra layer of "white hissing" noise on top of the quantisation noise. So now we have noise with extra noise, which is easy to hear on the TPDF dithered sound given by the SoX command above. Useless.
But wait. There is also something called "noise-shaped dithering". Let's take a look at that then.
Noise-shaped dithering to the rescue?
Basically, noise-shaped dithering is where you try to shape the dither, so that it becomes not so random anymore, again with the purpose of moving the noise to a different frequency. A simple noise-shape dithering technique is done by subtracting each sample value (of the applied noise) with the previous sample value. Because this will give a bigger chance of a higher frequency. So for a 44100 Hz signal, instead of the noise ranging between 11050 Hz and 22050 Hz, it will now be closer to 22050 Hz - which helps, because that's outside most people's hearing range. But for a 16 kHz sample on Amiga, it's still not a whole lot helpful. It'll merely bring the noise frequency closer to 8 kHz, which is still very audible to all of us.
For this reason, most of these noise-shaping dithering methods won't even let you process files with such low samplerates that we use on Amiga. The only one that will is called Shibata. And the SoX command looks like this:
sox 16bitinput.wav -b 8 8bitoutput.s8 dither -s -f shibata
It will be less noisy than the TPDF dithered output, but compared to the original truncated 8-bit version, it will sadly not reduce the noise at all.
At the low samplerates we use on Amiga, we don't have the option of moving the noise to a higher frequency outside the human hearing range. Our only option is to move it to a lower frequency. And SoX doesn't seem to do that.
Noise-shaping without dithering to the rescue then?
There is another tool out there called "Shibatch Sample Rate Converter". Like most of the SoX dithering methods, SSRC also refuse to work with lower samplerates. Lucky for us though, I'm a super hacker, so I took a look at the source code, and did some messy hacking experiments with the options. (Basically I just changed a couple of numbers so that the tool wouldn't dismiss my attempt using a lower samplerate than those supported, but if anyone asks, I was a super elite WhiteHat haX0r Uber geek who changed the world for the better - or better yet: Say that it can't be done any better! That way, we know someone will invest loads of time and effort to prove us wrong and provide an even better method in the near future).
I simply changed one of the profiles to "54264 Hz -> 27132 Hz". So that I have to feed it a 16-bit 54264 Hz file, to get an 8-bit 27132 Hz file back. To do this I obviously have to convert my 44100 Hz file to 54264 Hz first:
sox my16bit44100hz.wav -D -r 54264 my16bit54264hz.wav
And then I run my SSRC command:
ssrc_hp --twopass --bits 8 --dither 0 --pdf 1 0.1 --rate 27132 my16bit54264hz.wav my8bit27132hz.wav
Notice I apply "--dither 0" which means I'm not actually doing any dithering anymore. This is all "just" noise-shaping.
The saying goes that the human ear can hear between 20 Hz and 20 kHz. But this actually only applies to young people. The older we get, the less we're able to hear the higher frequencies.
Already at age 24, the highest frequency we can hear has dropped to around 17 kHz. At age 30 the top frequency is 16 kHz. At age 40 we're down to 15 kHz and at age 50 it has dropped to 12 kHz!
When we take a 16 kHz 16-bit sample and truncates it to 8-bit, the resulting quantisation noise appears to be anywhere between 2 kHz and 8 kHz. Everyone can hear those frequencies, regardless of age. In fact, the frequencies in that area are the ones we are the most sensitive to, which means it's the worst possible placement of unwanted noise.
All noise-shapers work by moving the noise to a different frequency range, preferably one completely outside our hearing range. Shibatch Sample Rate Converter moves noise up to a higher range. For a 27.132 Hz samplerate for example, noise is moved up to between 7 kHz and 13,5 kHz.
To illustrate, here's a visual presentation of a random bass sample (meaning the actual tone is in the lower frequencies) - truncated vs SSRC.
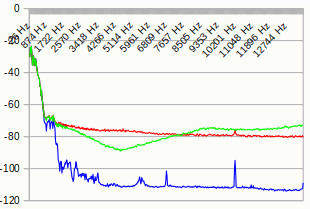
The red line is the normal 8-bit truncated version. The green line is the 8-bit SSRC version. And the blue line is the 16-bit original.
You can see in the SSRC version that the noise level at 4,5 kHz is as low as -89 dB. Then it climbs up to about -74 dB at 9 kHz where it stays. The truncated version has about -74 dB of noise at 4,5 kHz, then slowly dropping to -79 dB at 13,5 kHz.
That means the noise at 4,5 kHz in the SSRC version is actually 75% less loud than in the truncated version. That's an amazing result. But in return, the noise level above 9 kHz in the SSRC version is roughly 25% louder than the truncated version.
So if you're a younger person capable of hearing up to 13,5 kHz, then you will actually hear more noise in the SSRC version than in the truncated version. But if you're an older person, the SSRC will sound almost noiseless!
What can we do with this information? Well, you can decide if you want to use SSRC or not. If your primary target group consist mostly of older people, then SSRC would be a good choice. Just don't try to impress younger people with the "amazing Amiga audio quality".
So SSRC is definitely on the list of useful methods to reduce noise in our MODs. But the downside is that it forces us to use a samplerate of 27132 Hz... And that's another thing to keep in mind when using the SSRC method: As soon as you play the sample at other samplerates, the noise-reduction effect may disappear. It may even result in more noise than the truncated sample will give.
The least amount of quantisation
For the next experiment, we will pick the sample values that results in the least amount of quantisation. If for example we start at a 16-bit value of 10, and the next sample value is 240. Then the least amount of quantisation for the 8-bit samples would be 0 and 1, instead of 0 and 0 which will normally be the case for a truncated 8-bit sound. That way the quantisation will be 10 and 15 instead of 10 and 240, which will logically reduce the noise a bit - move it to a lower frequency - but it will also change the actual sound. It will kind of constantly move the DC offset, and can therefore easily result in the sound moving outside the available amplitude. Comparing a normal sound with the sound produced by this method, we can see how the sound wanders off and leaves the window.
Normal Sample:
Sample with least amount of quantisation per sample:
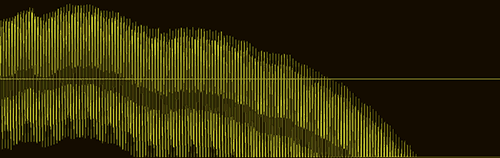
While it's clear for me to hear that the noise has indeed been moved to a lower frequency, it's also clear to see that this approach will only work for short sounds.
Here's a visual presentation of the bass sample that is used in the example, truncated version vs LAQ version.
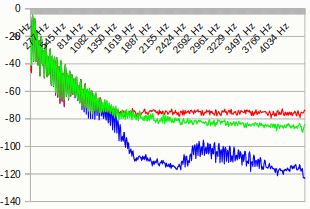
The red line is the 8-bit truncated version. The green line is the 8-bit LAQ version. And the blue line is the original 16-bit version.
Notice how the LAQ method cuts away about 9 dB of noise in the higher frequencies of the sample compared to the truncated version. That's almost half the noise gone. Enough to make a difference.
In return, the lower bands around 8 Hz has increased from -41 dB to -20 dB (impossible to see on the graph though), which means the loudness in that band has doubled - twice. But we don't care about that, because no human being can hear 8 Hz. And even if we could, it would be filtered away by our speakers and/or headphones anyway, because most of them doesn't support a frequency that low.
So when the LAQ method works, it works rather well. But it may require a bit of luck to get working, depending on the waveform.
The higher the samplerate, the less effective the LAQ method becomes. You'll be able to hear a big difference with lower samplerates, and then a decrease in the effect the higher samplerate you use. In other words, LAQ is only useful for bass instruments and such. But those has also always been the worst in regards of noise, so that suits me fine.
14-bit remains the ultimate solution
The final method on the list is the 14-bit trick, in which you need two channels and two samples. One 8-bit sample played at full volume + one 6-bit sample played at volume 1. This will give you a 14-bit'ish quality output, which gives the absolute best result of all the options - despite using lower samplerates.
So which method is the best?
Well, the best method is the one that works best for the specific case. Most of the time, the best result is produced by using a mix of different methods. Because each method has advantages and disadvantages.
Method | Advantage | Disadvantage
--------------+-----------------------+-----------------------------
Dithering | No advantages at all! | More noise
--------------+-----------------------+-----------------------------
SSRC | Moves noise up | Must be 27132 Hz
--------------+-----------------------+-----------------------------
LAQ | Moves noise down | Wanders off
--------------+-----------------------+-----------------------------
14-bit trick | Best result! | Requires 2 channels & sounds
--------------+-----------------------+-----------------------------
The SSRC method is useful when you know your primary target group mainly consists of older people - which is often the case on Amiga.
The Least Amount of Quantisation method is useful for short samples at lower samplerates, such as bass samples.
The 14-bit trick has the disadvantage of needing 2 channels and 2 instruments, but it doesn't necessarily require more bytes than the SSRC method. I've found this method to be rather good for creating basslines with far less noise than plain 8-bit bass sounds has.
And that concludes my quantisation noise-reduction experiments. I hope some of you found it useful. :-)
Back to table of contents